April 06, 2020 / by Giorgia Cantisani / C-NMF
Neuro-steered music source separation with EEG-based auditory attention decoding and contrastive-NMF
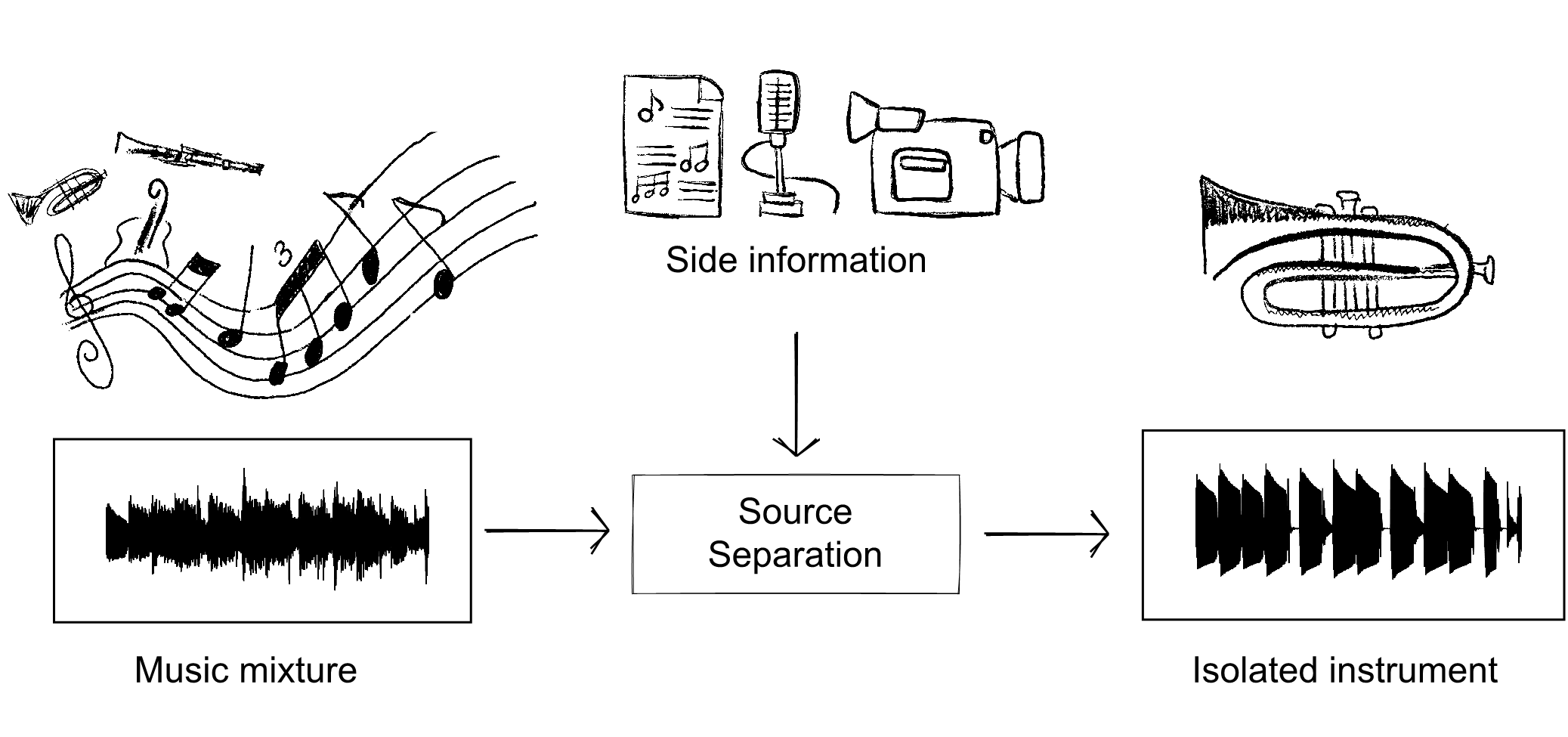
Music source separation is the task of isolating individual sources, such as singing voice, bass etc., which are mixed in an audio recording of a musical piece. A source separation system can be used directly by the end-user (e.g. a musician or a sound engineer) or be an intermediate step of other downstream tasks such as music transcription, score following, and many others.
State-of-the-art source separation systems are generally based on supervised deep learning, where a large collection of mixtures and corresponding isolated sources is needed for training. However, despite the release of dedicated datasets, it is still hard for those models to generalize to unseen test data with significant timbral variation compared to training.
A possible solution to mitigate this issue is to inform the system with additional knowledge about the test data. In this case, the approach is referred to as informed audio source separation and, if this additional information comes from another modality than the audio itself (e.g. the score, lyrics, visual cues, etc.), as multimodal source separation.
The user himself can be considered a rich source of information. Beyond manual annotations, our body's reaction to music manifests itself through many physiological phenomena (e.g. heartbeat variability, body movements, neural response).
Among those responses to music, we focused on the neural response characterized by electroencephalographic signals (EEG) and on the concept of selective auditory attention, i.e. the cognitive mechanism that allows humans to focus on a sound source of interest. This is known as the cocktail party problem and was studied mostly concerning speech perception in noisy or multi-speakers’ settings. It was observed that the attended source's neural encoding is stronger than the other ones making it possible to decode the auditory attention, i.e. determining which sound source a person is "focusing on" by observing the brain response.
In the case of music, one can recast the problem as one of decoding the attention to a particular instrument playing in the ensemble. However, this transposition is not straightforward. Unlike in the cocktail party problem where there is one source of interest to separate from unrelated background noise or speakers, music consists of multiple voices playing together in a coordinated way, making both the decoding and the separation problems more difficult.
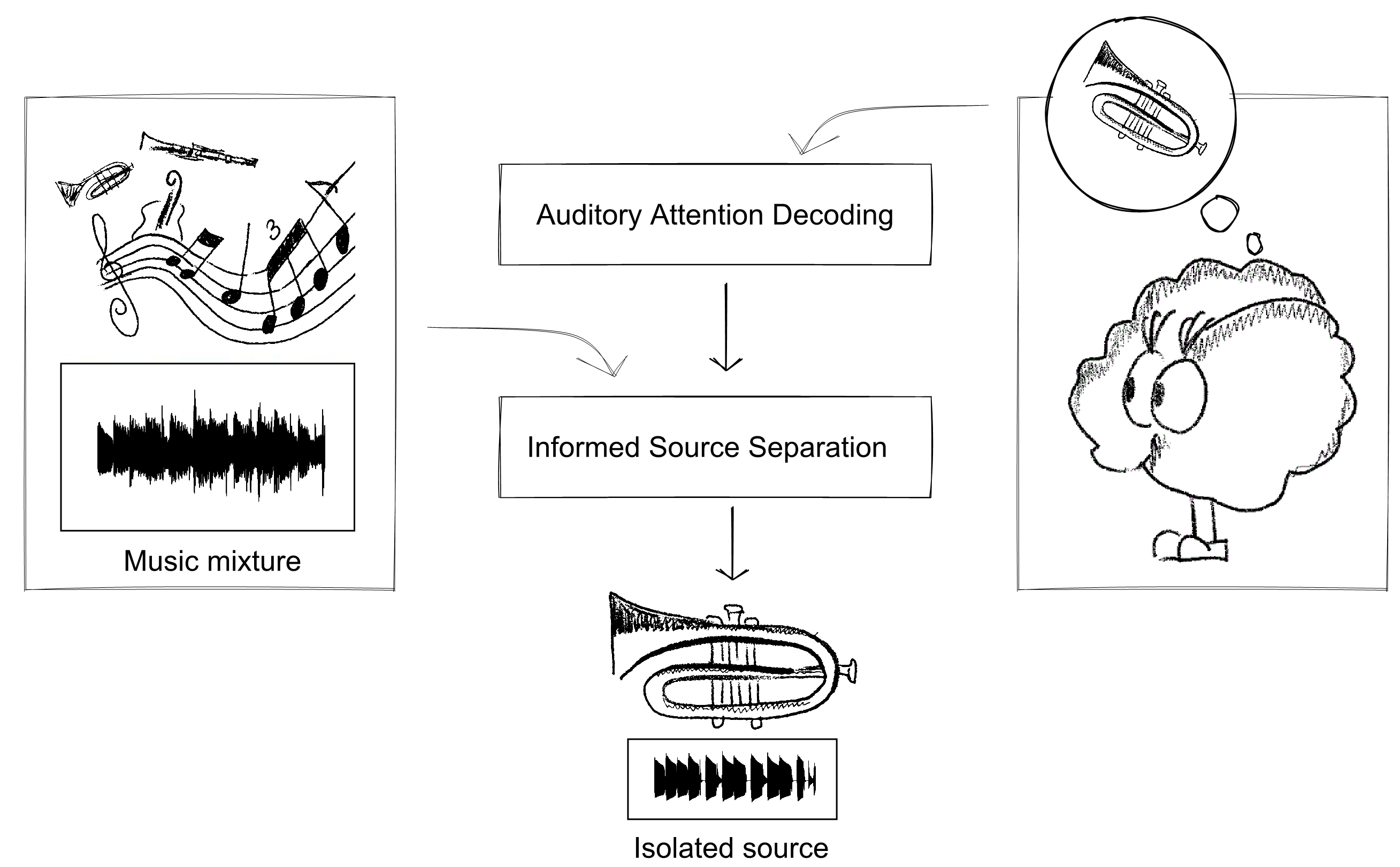
The user's selective attention can be used as a high-level control to select the desired source to extract and provide priors about it. This guidance can help the separation process but also give the user an interactive and improved listening experience. Therefore, we first studied the problem of EEG-based auditory attention decoding (AAD) applied to music, showing that the EEG tracks musically-relevant features highly correlated with the attended source and weakly correlated with the unattended one. Second, we leveraged this "contrast" to inform an unsupervised source separation model based on a novel non-negative matrix factorization variant, named Contrastive-NMF (C-NMF) and automatically separate the attended source.
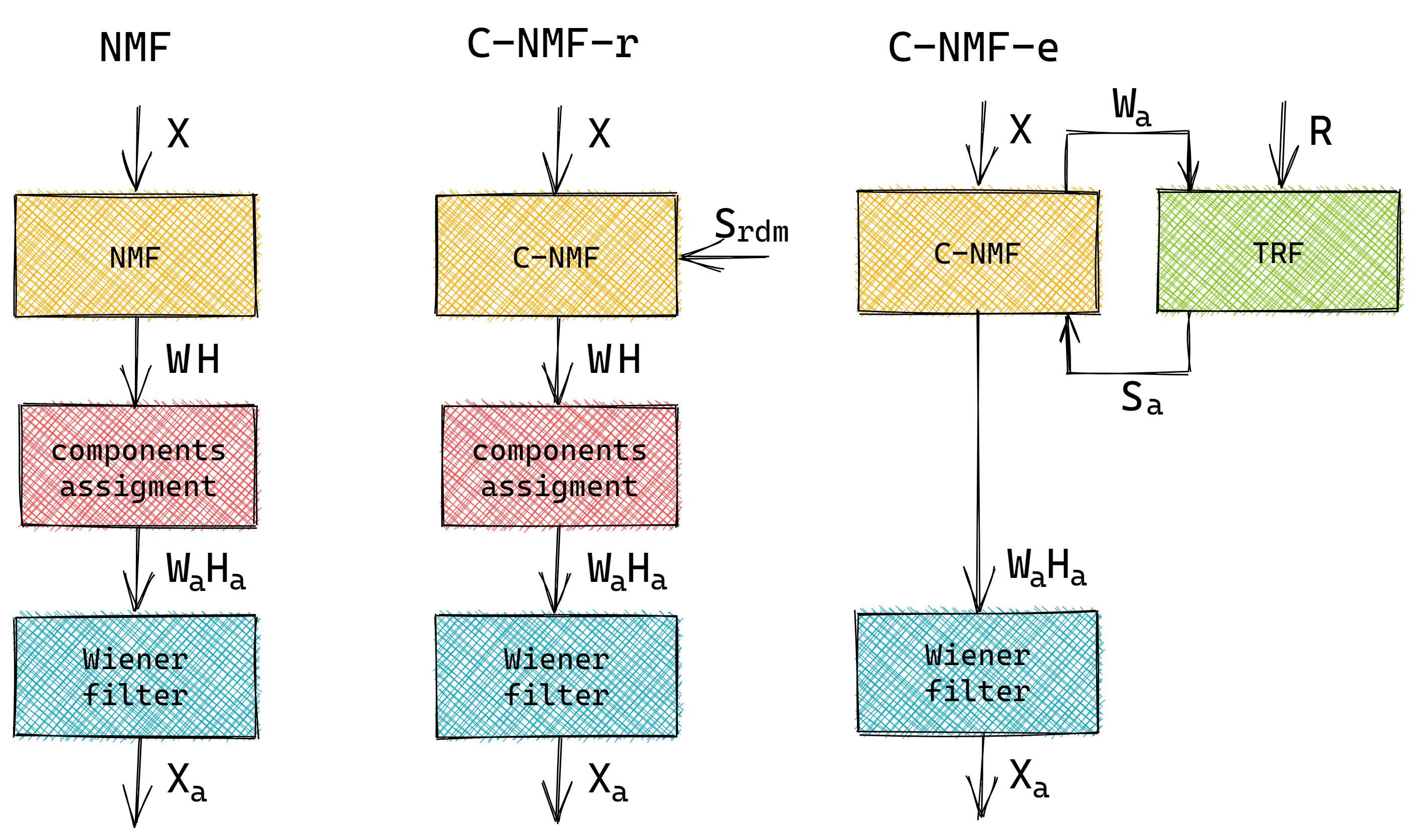
The experiments are designed to evaluate whether the EEG information helps the separation process (C-NMF-e). However, to verify that the improvement is due to the EEG and not to the model's discriminative capacity, in addiction to the blind NMF (NMF), we built a second baseline which consists of the C-NMF to which meaningless side information is given (C-NMF-r). As the models are entirely unsupervised, the factorized components need to be assigned to each source before applying the Wiener filter. In the two baselines, the components are clustered according to their MFCC similarity. In the case of the C-NMF-e we do not need this as the EEG information automatically identifies and gathers the target instrument components.
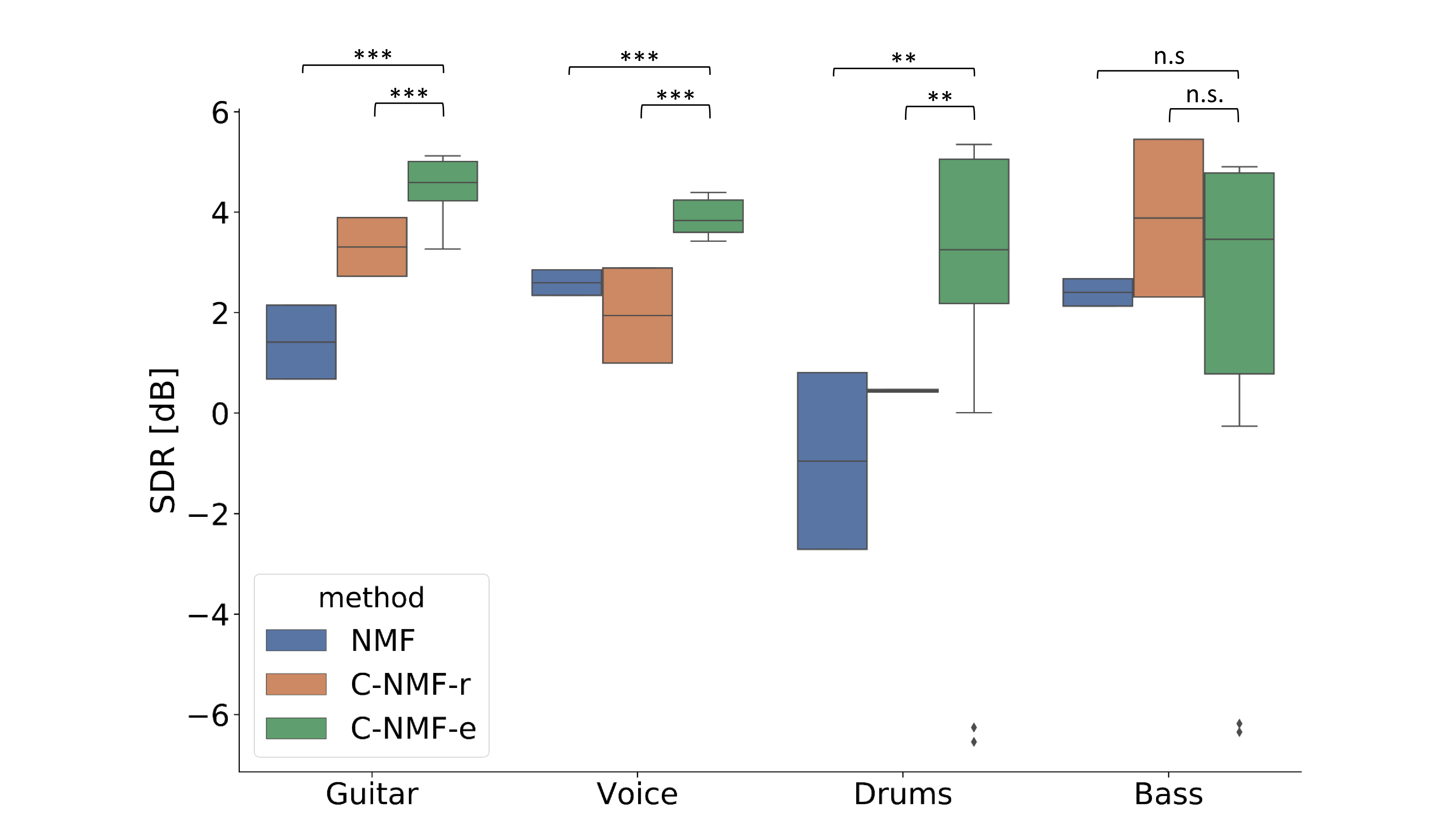
In Figure, one can compare the SDR obtained for different methods and instruments in the dataset. For all the instruments except for the Bass, our model performs significantly better than both the blind NMF and C-NMF-r. The high variance experienced when separating the Bass and the Drums is due to the high variance experienced across different subjects.
The audio examples are taken from the test set which is described in the paper. For the proposed model C-NMF-e, we propose several examples which are related to different subjects and different spatial renderings.
Vocals
Bass
Drums
Guitar
For more details, please refer to the paper Neuro-steered music source separation with EEG-based auditory attention decoding and contrastive-NMF by Cantisani G. et al., WASPAA, 2019.
This project is part of my PhD Thesis conducted at Télécom Paris under the supervision of Professor Slim Essid and Gaël Richard.